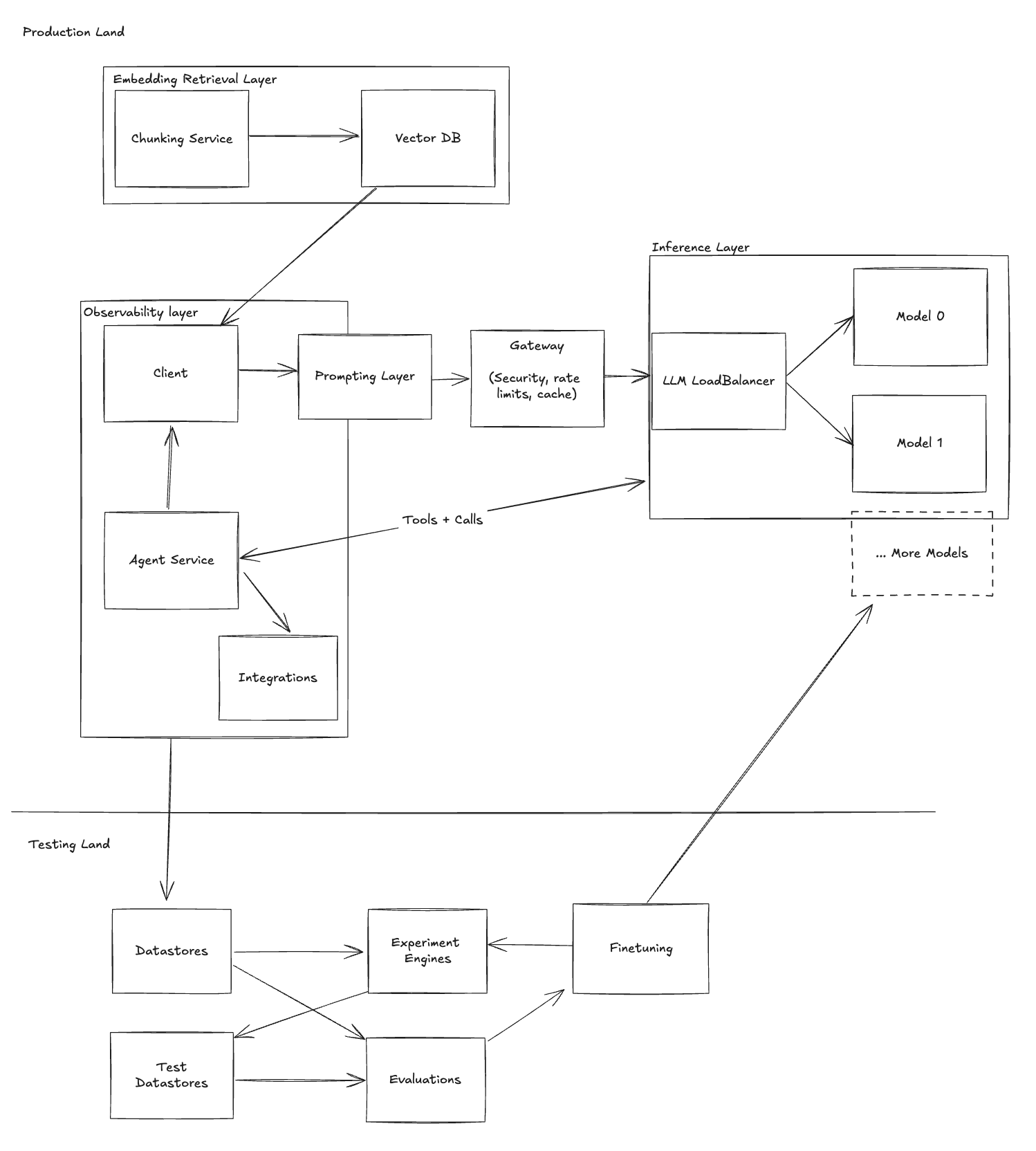
The Evolution of LLM Architecture: From Simple Chatbot to Complex System
Figuring out the right tech stack can be challenging. This simplified guide illustrates how a basic LLM chatbot application can evolve in complexity.
At Helicone, we’ve observed thousands of LLM applications at various scales. This article generalizes the different stages that most applications typically go through.
We also wrote a complementary blog that delves deeper into the LLM Stack and Helicone’s role within it.
Example: Evolution of a Chatbot
Let’s consider a simple internal chatbot designed to help employees of a small business manage their inbox.
Stage 1 - Basics
Initially, you can simply copy and paste the last 10 emails into the context.
System:
HERE ARE THE LAST 10 EMAILS IN THE INBOX
EMAILS: [{
...
}, ...]
Answer the user questions.
User:
What is the status of the order with the id 123456?
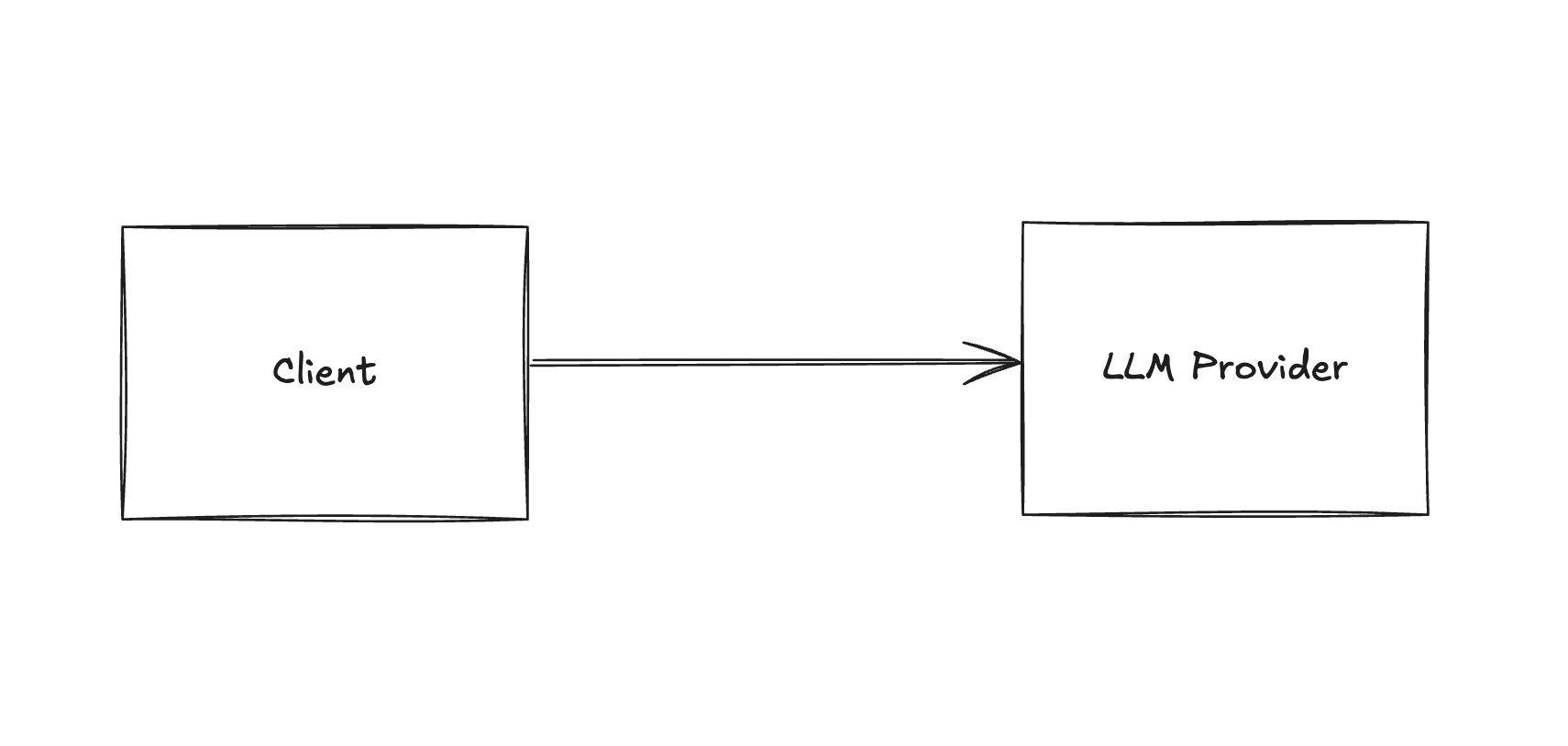
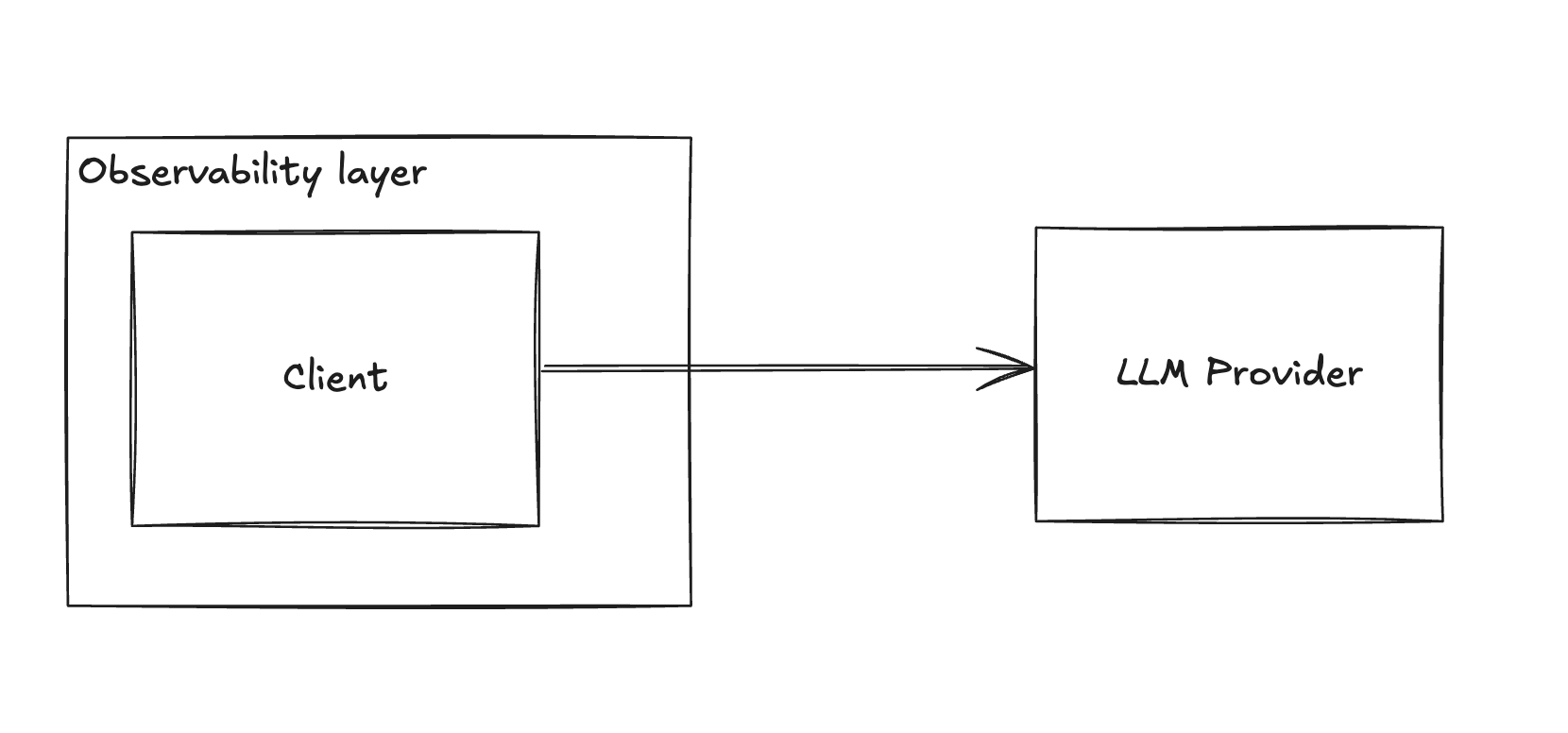
Stage 2 - Observability
As your app gains popularity, you may find yourself spending $100 a day on OpenAI. At this stage, basic observability becomes essential.
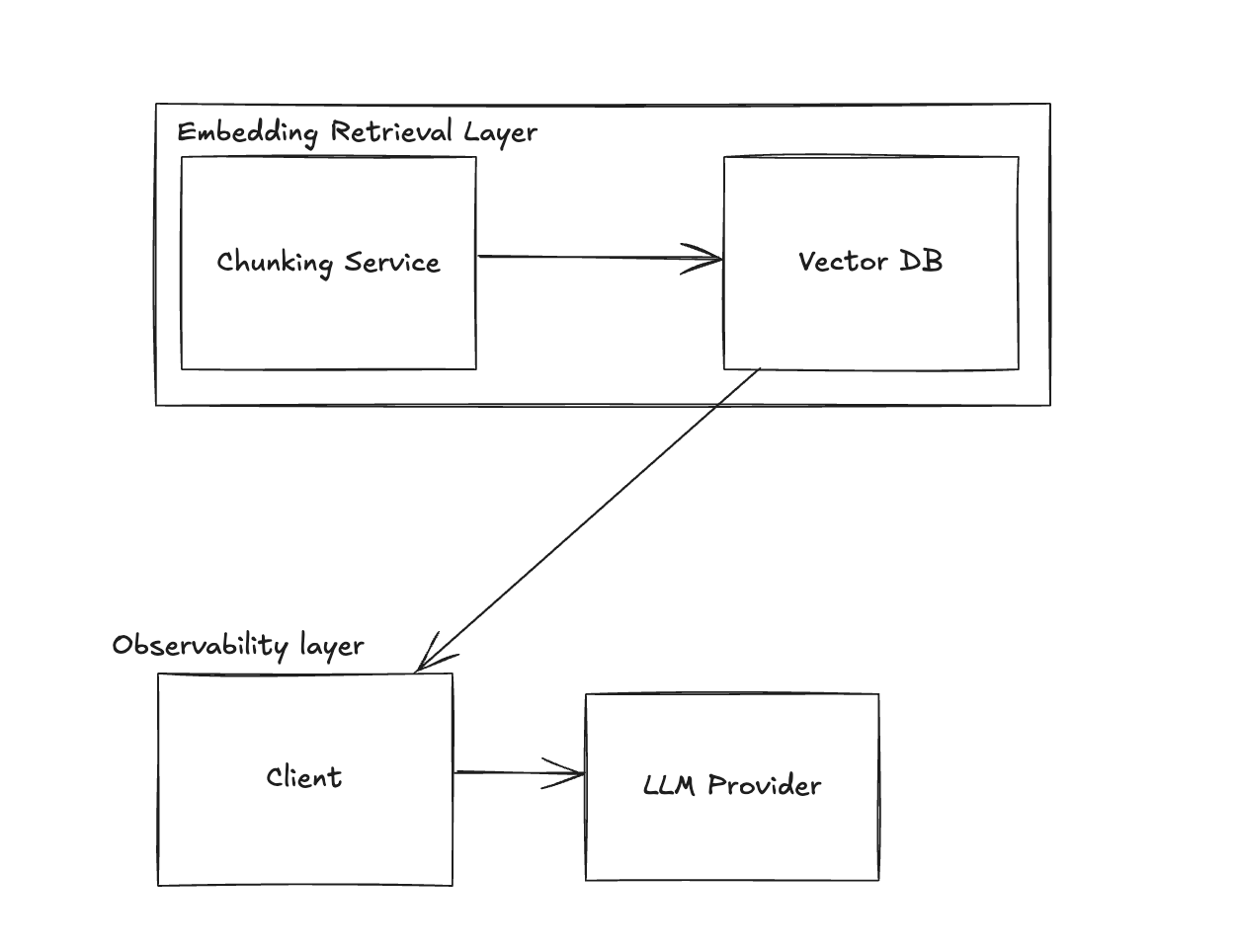
Stage 3 - Scaling
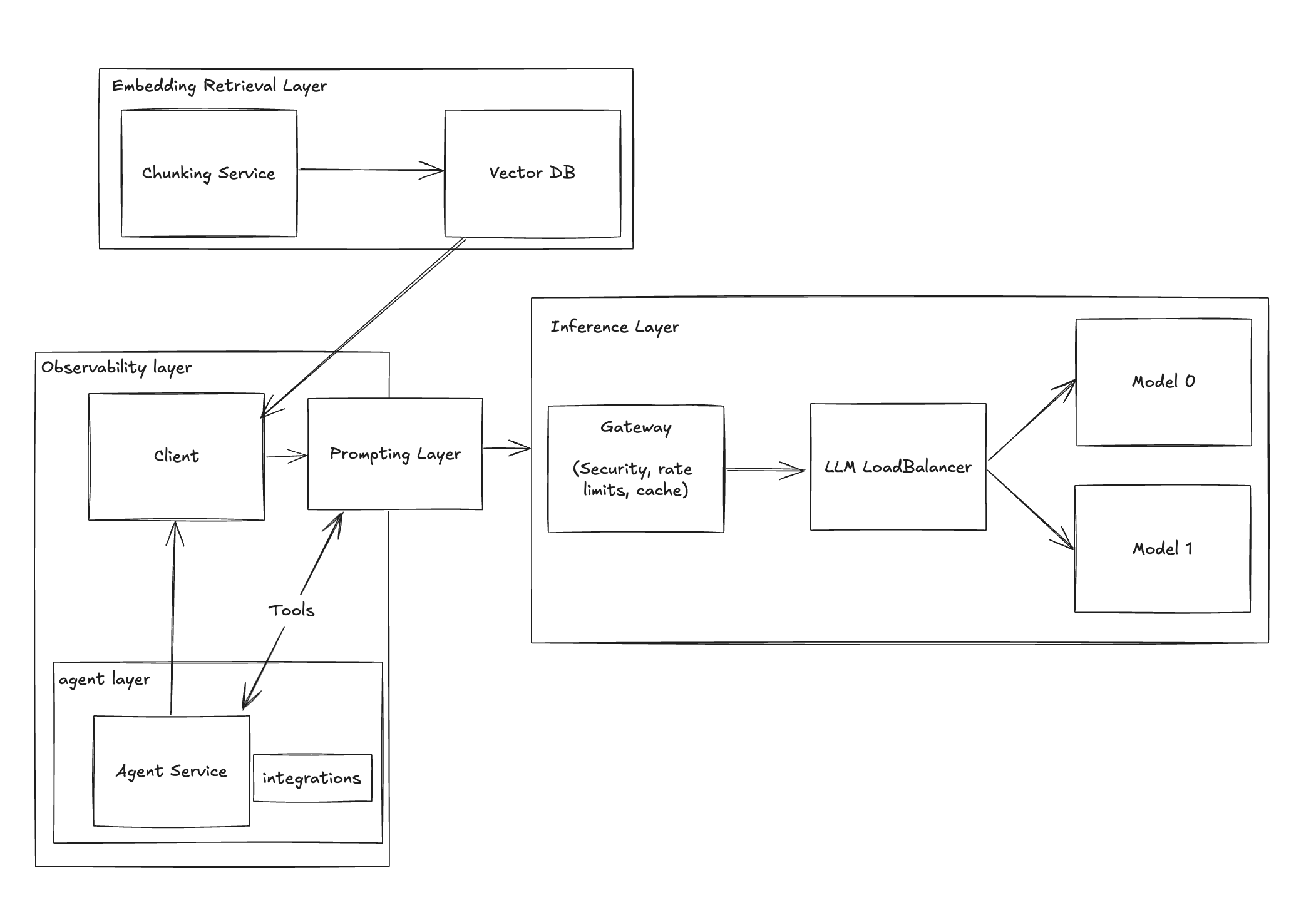
Users may complain that the chatbot only considers the last 10 emails. To address this, implement a Vector DB to store all emails and use embeddings to retrieve the 10 most relevant ones.
Stage 4 - Gateway
To manage costs, you may need to rate-limit users and add a caching layer. This is where a gateway comes into play.
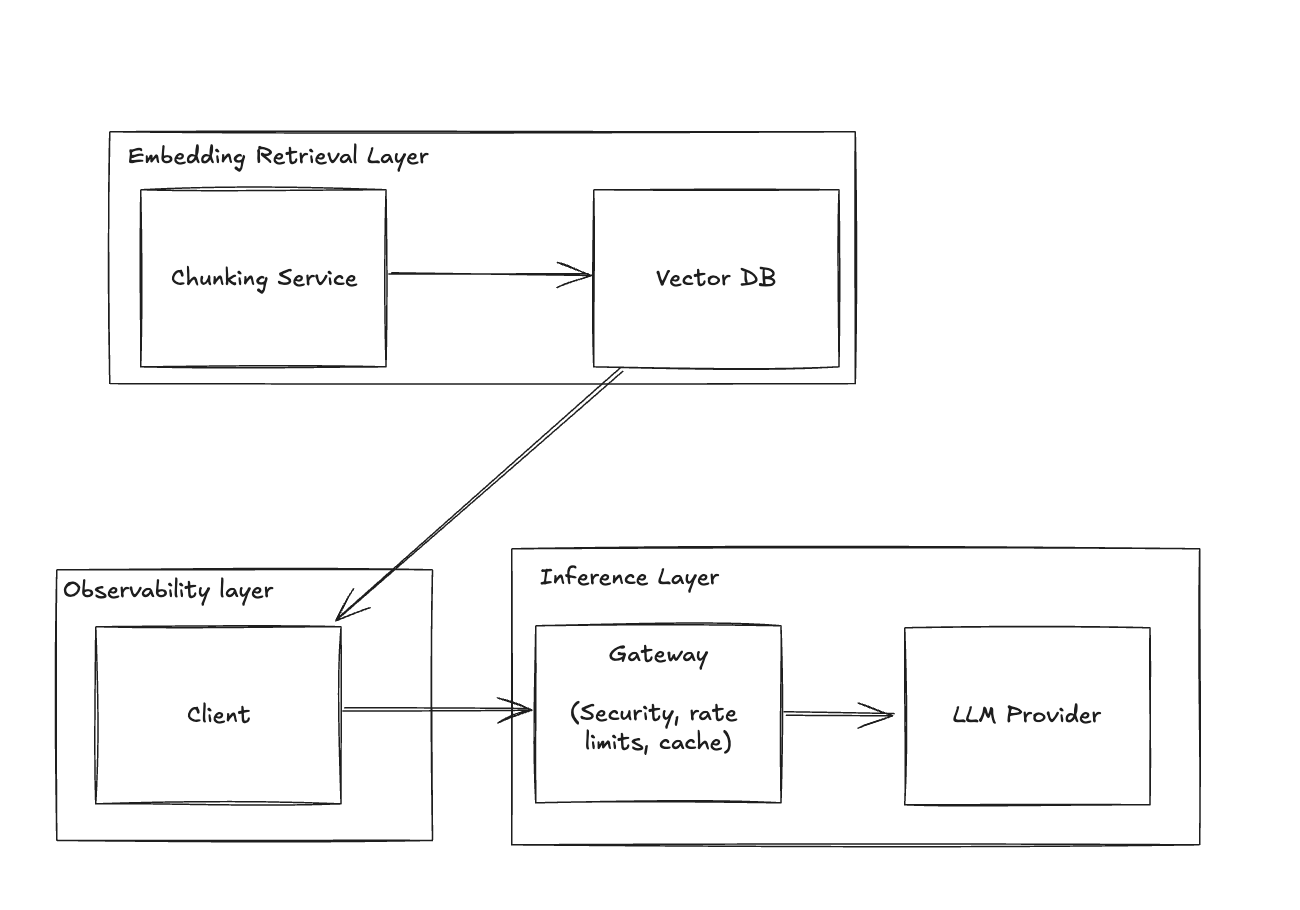
Stage 5 - Tools
Enhance functionality by adding tools that perform actions on behalf of users, such as marking emails as read or adding events to a calendar.
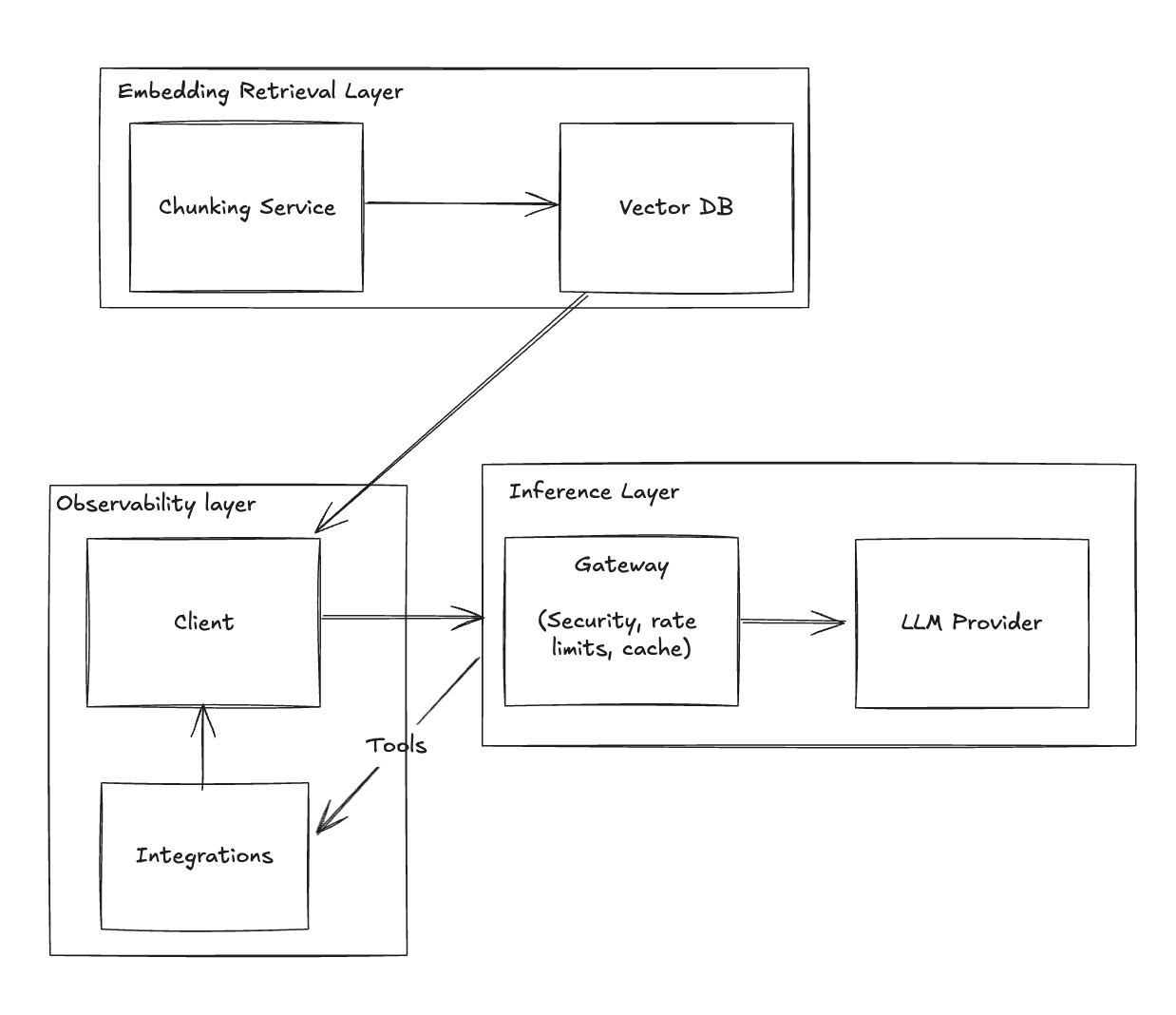
Stage 6 - Prompting
Implement a robust prompt management solution to handle prompt versions for testing and observability.
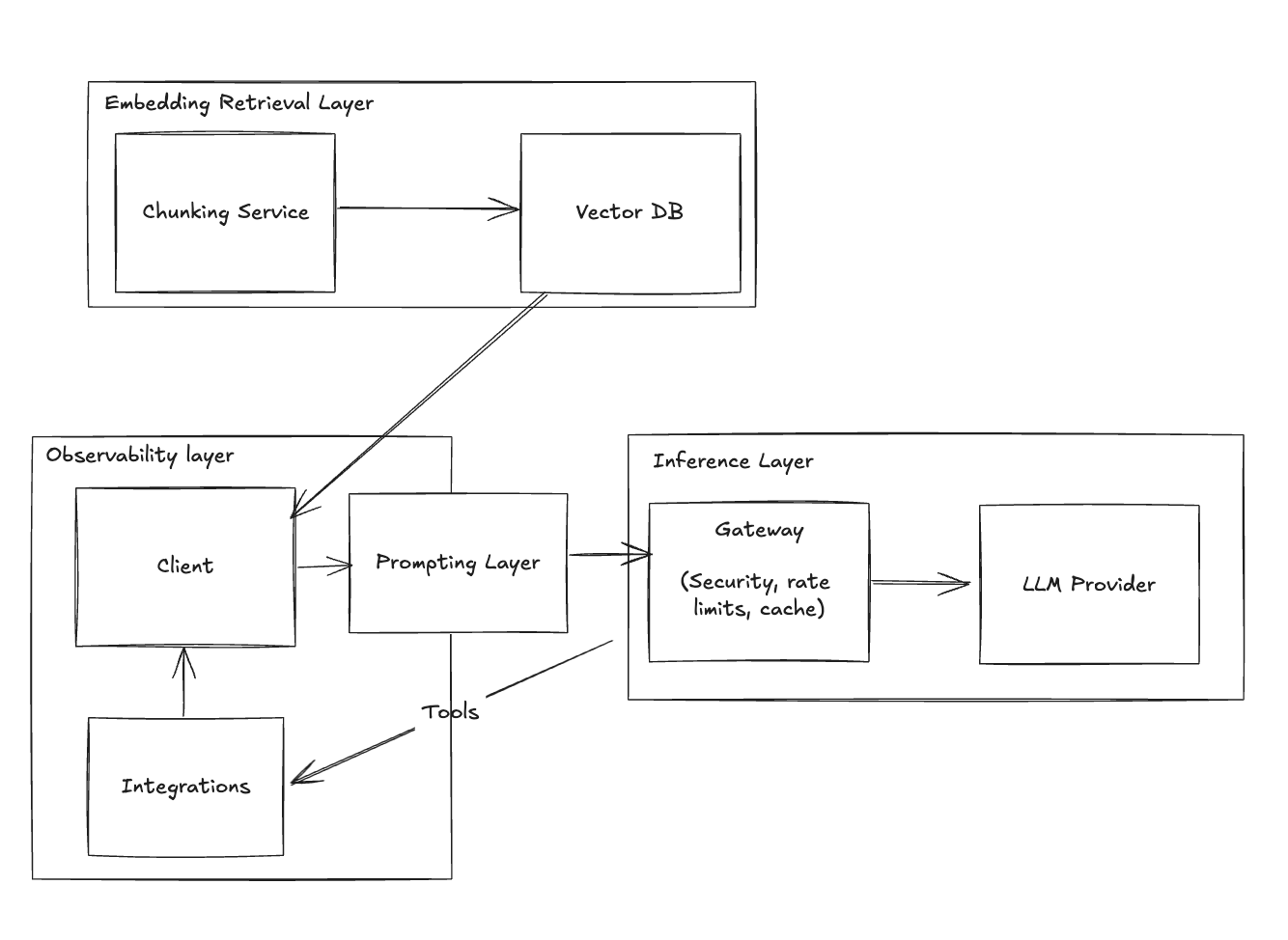
Stage 7 - Agents
Some actions may require multiple tool calls in a loop, where tools decide on the next action. This is where Agents come into play.
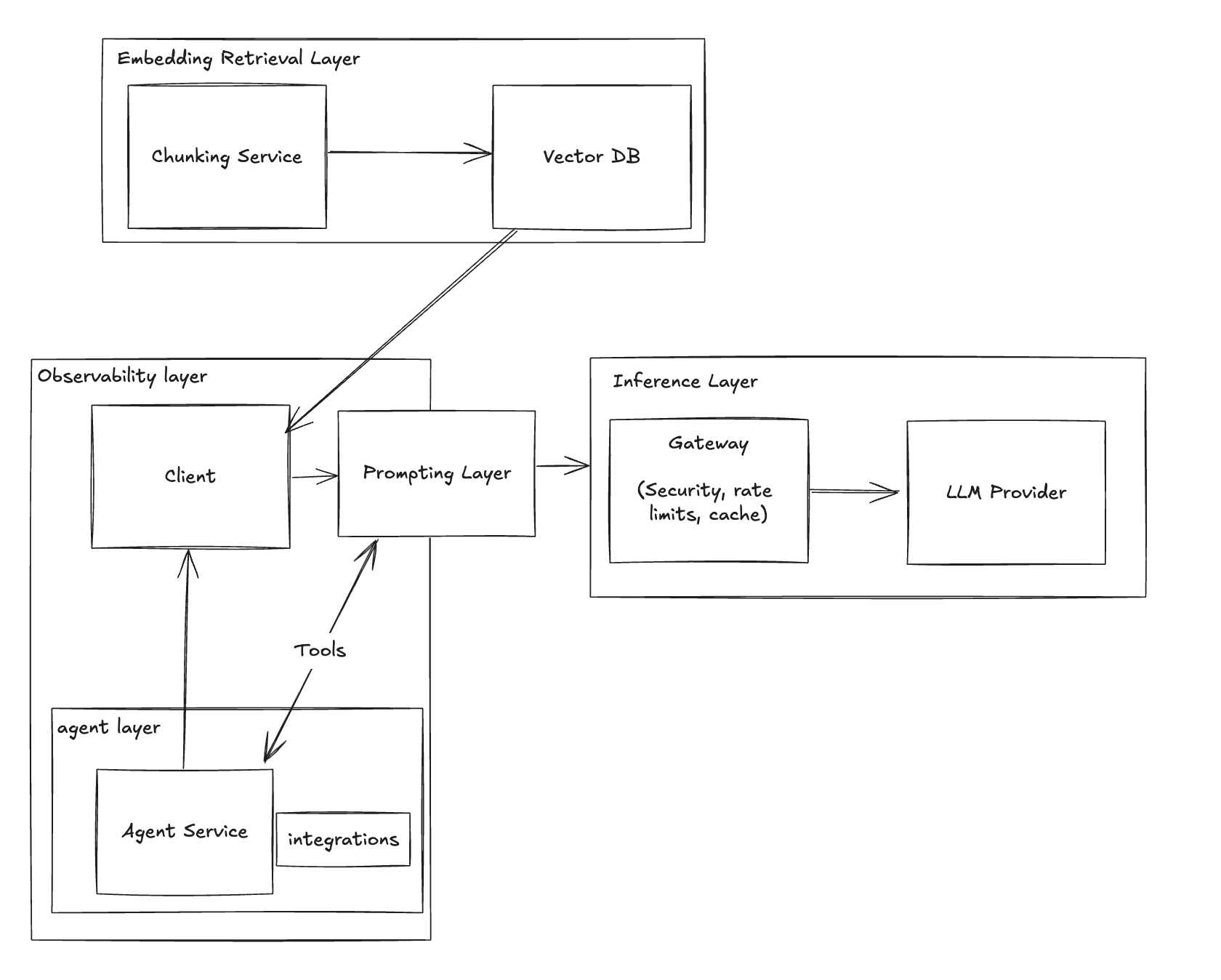
Agents are advanced integrations that operate within complex environments, allowing for sophisticated interactions through prompts instead of direct provider calls.
Stage 8 - Model Load Balancer
As your application grows, different models may be better suited for specific tasks. A model load balancer can help distribute the workload effectively.
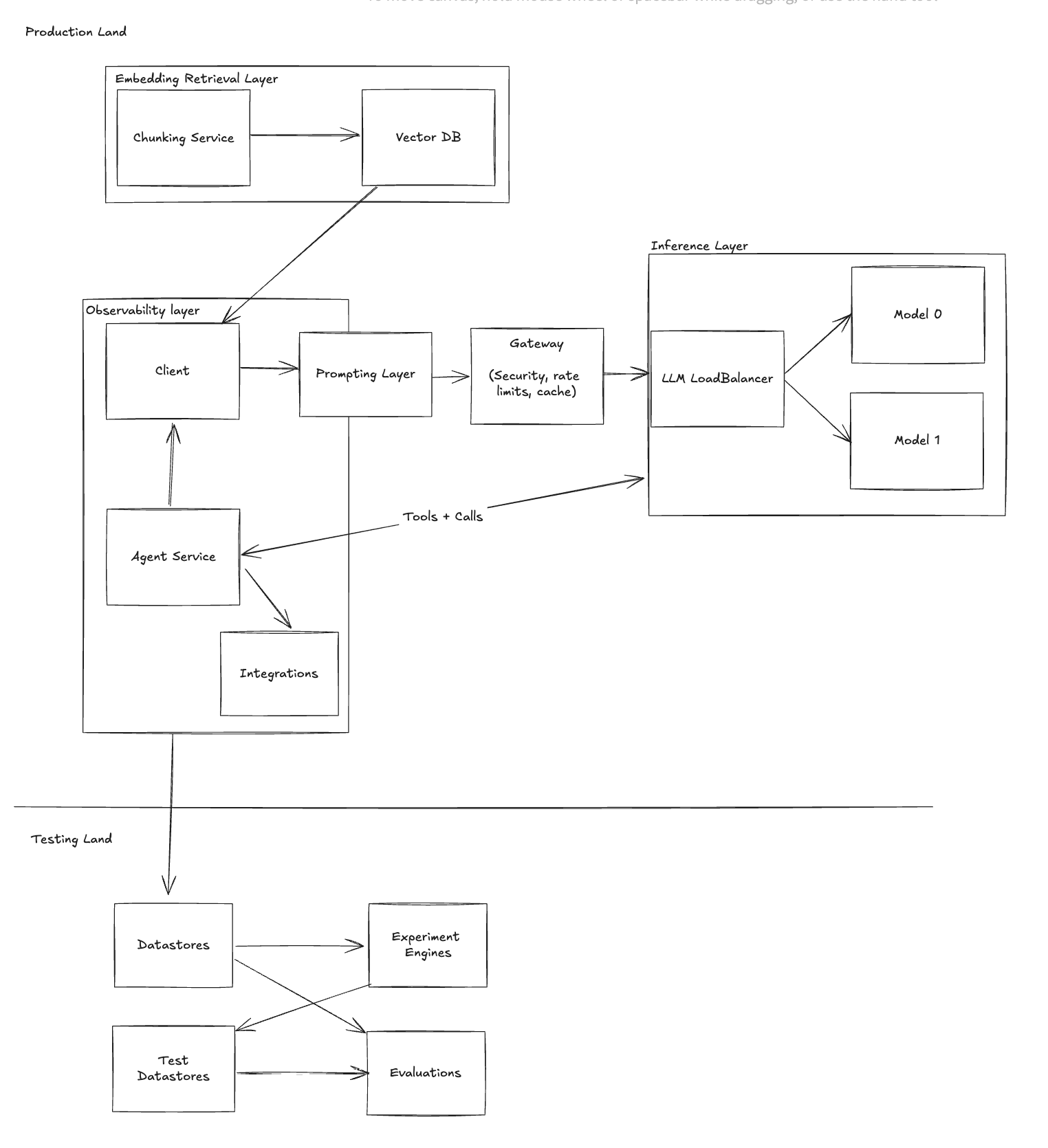
Stage 9 - Testing
To make data actionable, implement a testing framework that provides insights and evaluators to assess the quality of your model’s outputs.
Stage 10 - Fine Tuning
Fine-tuning is typically employed for workloads requiring significant customization, especially when optimizing for specific problems or cost savings.